Es gibt bereits unzählige Artikel über die berühmt-berüchtigte „blank-row“ in Power BI. Diese entsteht, wenn Beziehungen zwischen zwei Tabellen nicht korrekt aufgehen, also zum Beispiel in der einen Tabelle mehr IDs aufgeführt sind, als in der anderen.
Auf der anderen Seite kann es aber auch „zu viele“ Daten geben, wenn zum Beispiel die Kundenstammdaten- Tabelle alle Kunden enthält, die Fakten- Tabelle aber begrenzt ist.
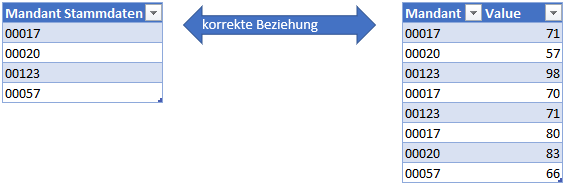
Konzeptuell sieht dies so aus:
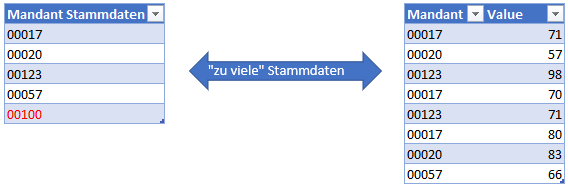
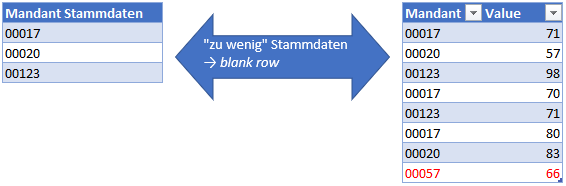
Die Gründe dafür können vielfältig sein: die Fakten-Tabelle zeigt nur einige wenige Jahre an, die Mandanten- Tabelle aber alle Stammdaten, oder die Mandanten- Tabelle muss manuell gepflegt werden und wurde nicht nachgehalten, oder oder oder.
So oder so ist die Anzeige in Power BI nicht benutzerfreundlich: entweder (bei zu vielen Stammdaten) muss aus einer eeewig langen Liste ausgewählt werden, welcher Mandant gefiltert werden soll, und man hat keine Indikation, bei welchem Mandanten überhaupt Daten vorhanden sind. Oder Im Slicer startet die Auswahl mit (blank), in dem dann die Values zusammengefasst werden, zu denen es keinen Mandanten in den Stammdaten gibt.
Nun gibt es zwei logische Lösungen dafür:
- „zu wenig Stammdaten“:
Die Fakten- Tabelle wird auf die Stammdaten- Tabelle gefiltert. Dann werden bestimmte Mandanten herausgefiltert – ob das gut oder schlecht ist, liegt am Report. (Mal davon ausgehend, dass der Fehler nicht an mangelhafter Datenpflege der Stammdaten liegt. Ansonsten natürlich -> Stammdaten nachpflegen!) - „zu viele Stammdaten“:
Die Stammdaten- Tabelle auf die Fakten- Tabelle filtern, sodass nur die Mandanten mit Bewegungsdaten gezeigt werden.
Hierfür gibt es wiederum zwei Möglichkeiten: ein Inner Join oder ein Filter mit List.Contains. Beide Möglichkeiten gehe ich hier durch.
In meinem Berufsleben waren „zu viele Stammdaten“ häufiger das Problem als zu wenige, daher nehme ich diese Tabelle als Beispiel. Das Vorgehen ist aber für beide gleich.
In den Beispielen unten arbeite ich mit den Daten aus den Screenshots oben: die eine Tabelle heißt „Facts“, die andere „StammdatenZuViel“
Inner Join
Eine sehr gute Darstellung der unterschiedlichen Join- Typen mit Erklärungen gibt es hier in der Microsoft Dokumentation:
Merge queries overview – Power Query | Microsoft Learn
Kurz zusammengefasst aber macht der Inner Join folgendes: er bringt nur die in beiden Tabellen enthaltenen Keys zusammen. Gibt es also in einer der beiden Tabellen mehr IDs als in der anderen, so behält er nur die übereinstimmenden.
Per Rechtsclick auf die Tabelle Facts in den Abfragen erstelle ich eine Referenz.
Die generierte Abfrage heißt nun Facts (2)
Über Rechtsclick auf die Spalte [Mandant Nr] entferne ich erst alle andere Spalten (dieser Schritt ist nicht unbedingt notwendig, aber erleichtert gleich die Wiedergabe des Ergebnisses) und auch die Duplikate.
Über die Stammdaten gehe ich nun über Start -> Abfragen zusammenführen -> Abfragen als neue Abfrage zusammenführen und wähle den Inner Join aus.
(In der Praxis würde ich die Abfragen nicht als neue Abfrage zusammenführen, aber wir haben ja noch eine zweite Möglichkeit, die ich gleich zeigen möchte und dafür benötige ich noch einmal meine Stammdaten. )
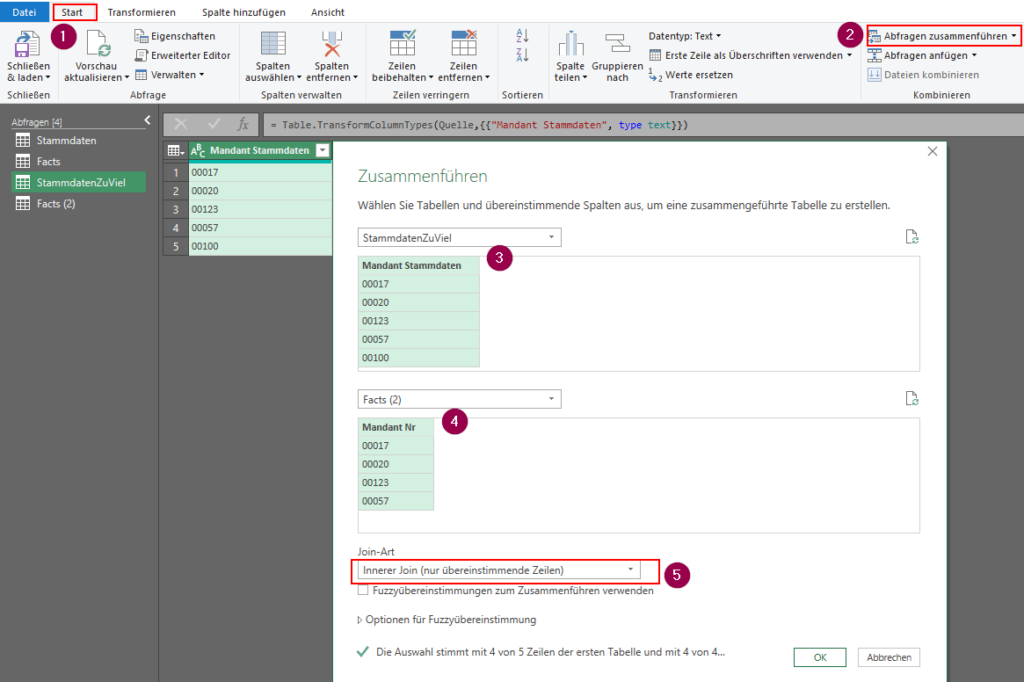
Der Output ist nun eine Tabelle, in der zwei Spalten existieren sollten: [Mandant Stammdaten] aus der Ursprungstabelle und Facts (2), die ich noch erweitern kann.
Man sieht direkt, dass nun nur noch 4 Stammdaten enthalten sind. Um die Spalten mit den Mandanten- Nummern nicht doppelt zu haben, lösche ich die erste Spalte wieder und habe nun nur noch die neue Spalte [Facts (2).Mandant Nr].
Die Stammdaten sind nun also angepasst auf die Fakten- Tabelle.
Wichtig ist an der Stelle noch zu erwähnen, dass das Erweitern des Inner Join vor dem Löschen der ersten Spalte [Mandanten Nr] geschehen sollte. So kann gegebenenfalls das „Query folding“ stattfinden und die Rechenleistung wird auf dem SQL Server getätigt.
Filter mit List.Contains
Einen Teil der ersten paar Schritte müssen wir wiederholen, also eine Referenz erstellen, andere Spalten entfernen, Duplikate entfernen.
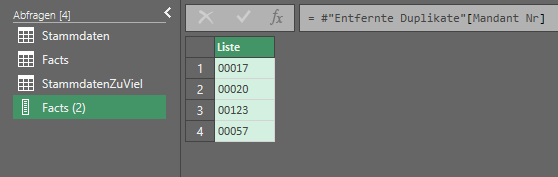
Anschließend entferne ich über erneuten Rechtsclick „Drilldown ausführen“ aus. Dadurch habe ich nun eine Liste erstellt, was man auch an dem Symbol neben Facts (2) sieht.
Der nächste Schritt wird nun im Erweiterten Editor für die Abfrage StammdatenZuViel durchgeführt. Dort stehen bisher für die Tabelle der Stammdaten nur folgende Schritte:
let
Quelle = Excel.CurrentWorkbook(){[Name="StammdatenZuViel"]}[Content],
#"Geänderter Typ" = Table.TransformColumnTypes(Quelle,{{"Mandant Stammdaten", type text}})
in
#"Geänderter Typ"
hier füge ich nun den folgenden Schritt ein:
#"Gefilterte Zeilen" = Table.SelectRows(#"Geänderter Typ", each List.Contains(#"Facts (2)", [Mandant Stammdaten]))
in
#"Gefilterte Zeilen"
Die Zeilen werden also auf die Formel List.Contains gefiltert, die die soeben erstellte Liste mit der Spalte [Mandant Stammdaten] abgleicht.
Hier wurde also das Äquivalent zum „in“- Operator in SQL geschaffen, und das ist auch die Stärke dieser Formel. Die komplette Last der Formel Auswertung erfolgt auf dem SQL Server.
Würde die Quelle kein SQL Server sein, sondern zum Beispiel eine Sharepoint List, wäre diese Möglichkeit im Vergleich zum Inner Join langsamer. Es gibt allerdings noch einen Optimierungsschritt: wir können diese Liste in den Puffer laden, damit die Abfrage (speziell bei großen Datenmengen) nicht erst erstellt werden muss. Dazu füge ich noch einen Schritt in meiner Liste „Facts (2)“ hinzu:
#"Puffer" = List.Buffer(#"Mandant Nr")
in
#"Puffer"